I am building a direct attached storage (DAS) case that I will attach to my workstation using an external SAS card. External RAID DAS cases for SAS drives are not cheap so homemade it is! So far I have been assembling the parts, I have the drives, case, and lots of wires. I will do a more in depth video of the whole process later. You could use this as part of a NAS if you wanted.
Category: Technology
Using Unraid for rsync (backintime) backup and External Drive Replacement
I decided to replace a bunch of external hard drives with an UNRAID server. Setup to work with rsync and backintime backup software for Linux. Managed to sort out an error with rsync and the samba shares not liking files that start with “._”. This is a great use of my UNRAID system.
UNRAID Update 2 – ZX-DU99D4 V1.11 X99 Motherboard Dual Xeon E5-2650LV3 with 64GB of Ram
I have the base components of my new UNRAID server. I got a Chinese X99 dual CPU motherboard off eBay, it’s the ZX-DU99D4 V1.11. Which I will be running two Xeon E5-2650LV3 with 64GB of Ram (both used of eBay). This will be a great base system for playing with VMs and dockers etc in UNRAID using the ZX-DU99D4, as well as running backups.
Lightworks and Opensuse Leap 15.2
Quick post on how to get Lightworks running on Opensuse Leap 15.2 as I ran into a few problems. I discovered that Opensuse Leap 15.2 is not officially supported by lightworks however it was relatively simple to get it working. The error I was getting was because the glibc version installed by Opensuse is too old. I think it is something like version 2.26 and lightworks needs version 2.29 or above. Why the version in opensuse is so old I do not know, we are on version 2.33 I think.
So what I did was download the rpm of version 2.33 from here, and extract it as an archive. I then found the required library that lightworks needed, “libm.so.6” which is a simlink to “libm-2.33.so”.
All that was then required was to copy both of those files into “/usr/lib/lightworks/” as that is one of the first places that lightworks looks for libraries. This seems to have solved the problem. I did not install all of glibc 2.33 as I think this would have caused problems elsewhere, and it seems that this is the only missing library that lightworks needed.
I haven’t had any problems since.
Unraid and BackInTime over SMB
I have recently setup a secondary server using Unraid to run backups (including with BackInTime). (I will do a full post about it at some point.) I will use this server as a BackInTime server for my Linux workstation, and the Time Machine server for my Mac laptops. Getting it working with the Macs was a bit of a pain, but I got there in the end. But today I shall talk about getting it to work with BackInTime, which I think I have now done.
I ran into a problem thar the standard rsync configuration used by BackInTime was not able to copy files that started with an ‘_’ from the workstation over to the smb share on the Unraid server. This was because when rsync made the temporary ‘._*’ file it would fail as smb doesn’t allow that file name. This was a problem because some of the software libraries that I was using for projects have files that start with ‘_’. So the result was that the snapshots were missing those files and completing with errors. Not ideal. The actual number of files that this affects is fairly low and I could probably live with it, but really it would be better if a solution could be found.
The solution
It turned out that the solution was fairly straight forward in the end. I had to disable the vfs objects fruit and streams_xattr for the share. Then it worked perfectly. The problem is that unraid sets those automatically for each share. So I have to manually delete them, and then restart samba each time I reboot the server. Fortunately that will not be very often.
Still, it would be better to find a more permanent solution. I am currently looking for that, and have posted to a couple of forums to see if anyone knows if it is possible to have custom settings for a share that are not overwritten each time the array is started.
Cloning System Disk with Clonezilla
I cloned my linux system disk with clonzilla. Ifs very straight ward, the video below shows you how I did it. Better than my other video as I recorded it into a HDMI capture card, gets around the dodgy camera angle of last time.
Home Server Upgrade
I needed more space in my home server so got another two 6TB drives, and I decided to also replace the system disk as it is pretty old. I cloned the existing drive using Clonzilla and then expanded the partitions to fill the available space. Check out the video for the full details.
Lenovo ThinkPad Carbon X1 (20KH) 6th Gen Linux (Ubuntu 18:04)
I have received a new Lenovo ThinkPad Carbon X1 (6th generation, mine is the 20KH model with NFC and the higher res screen) which I have been trying to get Kubuntu 18:04 LTS Linux running on. This has been largely successful with a few problematic areas. Mostly the trackpad. I am a fan of mouse pointer emulation, which allows you to do one finger tap for mouse left click, two finger for right click, and three for middle. This is what I haven’t been able to get working really.
The Trackpad
The problems with the trackpad are that it would be slow to start working on boot, and often when waking from sleep. Also mouse button emulation intermittently failed. This would be accompanied with CPU usage spikes that I think were some sort of driver crashing, trace state, or similar.
Edit: This is probably the fix we are looking for! Install xserver-xorg-input-synaptics (which for me is xserver-xorg-input-synaptics-hwe-18.04). The left ‘i2c_i801’ commented out of the ‘/etc/modprobe/blacklist.conf’. This seems to have got it. I now have a trackpad that works on boot and after waking from sleep. I also have the config controls in the settings. So I think this is the way forward. In addition, as the physical buttons did occasionally stop working after reboot, I suggest getting the pm-utils to run the following commands at wake up which I put in a bash script.
#!/bin/bash
#reconnects trackpad after sleep
case "$1" in
post)
echo -n "none" | sudo tee /sys/bus/serio/devices/serio1/drvctl
echo -n "reconnect" | sudo tee /sys/bus/serio/devices/serio1/drvctl
;;
esacThe best place for the bash script in Ubuntu 18.04LTS is in a file in /lib/systemd/system-sleep/ which I called trackpad, make sure you make it executable.
Possible fix one: Getting the trackpad working might require that ‘i2c_i801’ is commented out of the ‘/etc/modprobe/blacklist.conf’. This will fix the problems with it being detected on start and coming out of sleep.
However… possible fix two: You might have more success with leaving ‘i2c_i801’ on the blacklist and adding ‘psmouse.synaptics_intertouch=1’ to you grub config (‘/etc/default/grub’) and then running ‘sudo update-grub’. This seems also to work.
So this is the problem with intermittent faults. Getting to the bottom of the problem and the solution is very difficult. So I would suggest you try both and see what works better.
It will not however fix the problems with mouse click emulation intermittently failing. That I have not found a fix and instead switched it off altogether. You are then left with using the mouse buttons.
Sleeping
To get sleeping working correctly you need to make use that in the BIOS the sleep mode is set to Linux instead of windows. That is it. Without that then the system will not come in and out of sleep properly.
Other than these issues, and the WAN modem not working (no driver), the laptop seems to work well.
Moving Windows 10 install to an SSD
My fairly old Windows 10 machine was running very slowly, it was extremely annoying and I didn’t want to invest in a new machine. So moving the Windows 10 install to an SSD seemed like a option worth trying.
I didn’t want to get a new machine for two reasons really, one was I didn’t want to have to move all the data and apps etc to a new computer, and also I don’t use Windows much (so motivation was lacking). So investing in a new machine was also not really a high priority. I looked at the performance monitoring systems in Windows to try to figure out what the problem was. The machine at the time had 16GB of DDR2 ram, and 2 quad core AMD Opteron 2386 SE Processors (2.8GHz). Which, although isn’t super high spec (anymore) its not bad.
What was the problem?
Looking at the performance monitoring it became clear that it was the old system disk that was a 32oGB hard drive. Which was always at 100% use and just being hammered all the time. So decided that it was worth a shot to replace it with a SSD, to see if that would improve things enough to make the machine usable. If not I could use the SSD in a new system anyway.
The SSD Upgrade
I bought a 250GB SSD drive, which was plenty big enough, and cost about £30. The next question was what was the best way to move the system drive over to the new disk. In such a way that nothing would then need to be re-installed. On Linux this is fairly easy, there are a load of free software that can do this. I wasn’t so sure on Windows. However after a quick search I found a EaseUS Todo Backup Free 11.5 which worked very well. The tool has a disk or partition clone mode, which is the bit you want. Here you have to make sure that you select the whole system drive, as there is a bunch of recovery partitions etc. So in the picture below I would choose Hard Disk 0, which selects all the partitions.
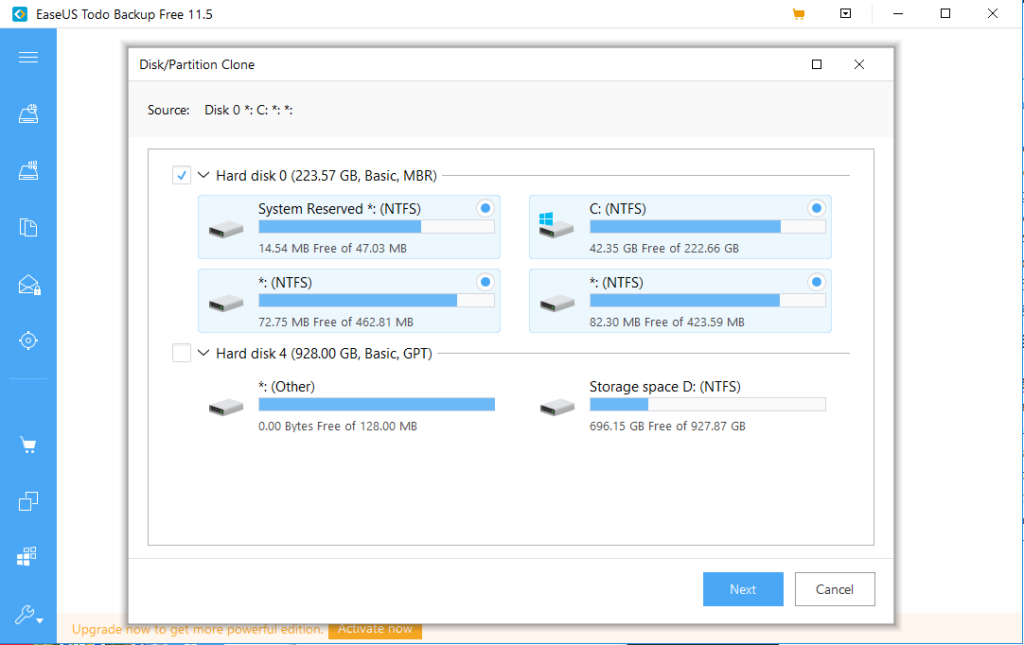
One the next screen you select the target drive. I cannot pick the target, as its not there. However you would select the SSD drive. For an SSD there is an additional step, where you should click ‘advanced options’ and and select optimise for SSD.
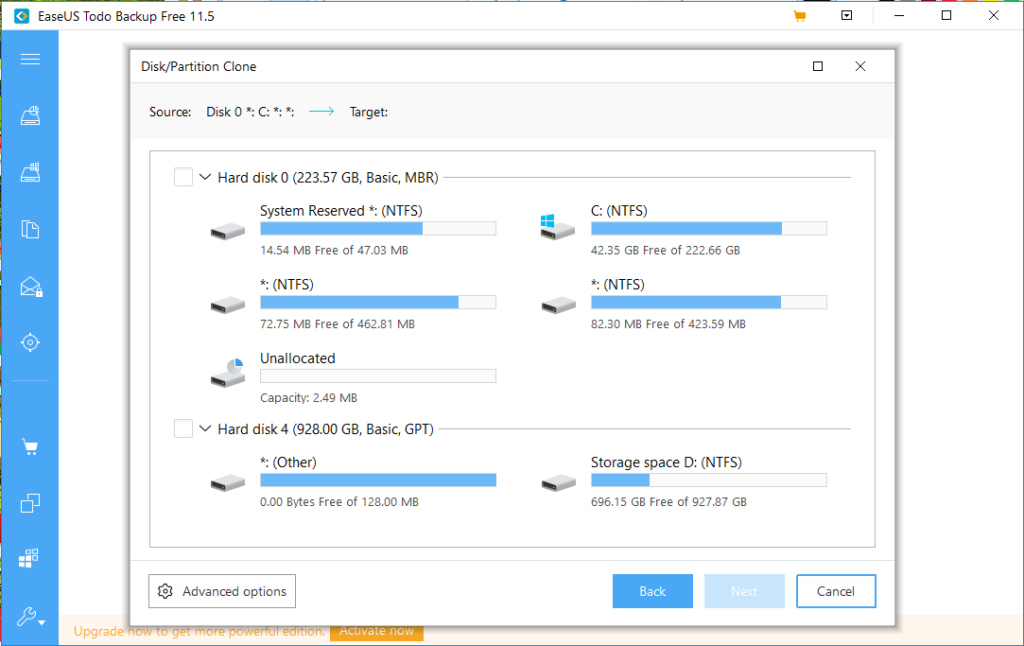
Once you have picked the target click next and then it is a simple process to start cloning the system drive onto the new SSD drive. This will take a little while and you can set the machine to shut itself down at the end.
You then just swap the drive over, and you might need to tell your computer to boot off that drive in the BIOS. It depends on if you have a load of other drives in the computer. All being well the computer will just boot up as normal, only with a bit of luck it will boot a lot quicker.
What was the outcome?
When I swapped the drive over I also put in different memory. I had a lot of memory from a server, so I put 32GB of ram in the machine at the same time. So I upgraded it to the SSD and 32GB of ram. The difference is huge!! It was well worth it, the machine is very much usable again. It boots in under a minute, and works well for what I use Windows for. This is a great option to put some life into an old machine. The CPUs and GPU in this computer are old, but the machine will do pretty much anything most people need.
You might have problems with updates after this saying that they cannot update the System Reserved partition. If you do then check out this guide from Microsoft about how to fix it.
Graph Visualisation with Neo4J and Alchemy
I have been using the Alchemy.js library to do some graph visualisation for netorks. Its pretty good, my default template is below as I had some trouble with those I found on around the internet.
It makes a simple graph with node labels visible, and takes the data as a .json file. I produce the data file from an R script that extracts data out of the Neo4J database. The basic code for that is below. One thing to remember with this is that the data file with the network in is easily accessible to anyone that might want to download it. So if it constitutes a lot of work and you don’t want anyone to get hold of it (e.g. if it is research you intend to publish at a later point), this isn’t the method for you.
<html>
<head>
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/alchemyjs/0.4.2/alchemy.min.css" />
</head>
<body>
<h1>Network Visualisation</h1>
<div class="alchemy" id="alchemy"></div>
<script src="http://cdn.graphalchemist.com/alchemy.min.js"></script>
<script src="https://d3js.org/d3.v3.min.js" charset="utf-8"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/alchemyjs/0.4.2/alchemy.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/alchemyjs/0.4.2/scripts/vendor.js"></script>
<script type="text/javascript">
var config = {
dataSource: 'data.json',
forceLocked: false,
graphHeight: function(){ return 1000; },
graphWidth: function(){ return 1000; },
linkDistance: function(){ return 40; },
nodeCaptionsOnByDefault: true,
"nodeCaption": 'name',
"nodeMouseOver": 'name'
};
alchemy = new Alchemy(config)
</script>
</body>
</html>
Here is the R code that generates json data file from the Neo4J database, its really simple. Connect to the local running Neo4J database, run a query to get the nodes, run a query to get the relationships (edges), and then I did some quick clustering analysis in iGraph. You need to do a bit of work to get the communities into the dataframe, if you cluster. You then need to do a little work to get the json file. Its pretty good an not a lot of code to get a nice visualisation from your Neo4J database.
library(RNeo4j)
library(igraph)
neo4j = startGraph("http://localhost:7474/db/data/")
nodes_query = "MATCH (a) RETURN DISTINCT ID(a) AS id, a.name AS name, labels(a) AS type"
nodes = cypher(neo4j, nodes_query)
rels_query = "MATCH (a1)--(a2) RETURN ID(a1) AS source, ID(a2) AS target"
rels = cypher(neo4j, rels_query)
ig = graph.data.frame(rels,directed=TRUE,nodes)
communities = edge.betweenness.community(ig)
memb = data.frame(name = communities$names, cluster = communities$membership)
nodes = merge(nodes, memb)
nodes_json = paste0("\"nodes\":", jsonlite::toJSON(nodes))
edges_json = paste0("\"edges\":", jsonlite::toJSON(rels))
all_json = paste0("{", nodes_json, ",", edges_json, "}")
sink(file = 'data.json')
cat(all_json)
sink()